Introduction
Electroencephalography (EEG) has emerged as a powerful tool for non-invasive brain-computer interface (BCI) applications, particularly in decoding speech directly from neural signals. This project explores the feasibility of translating EEG data into intelligible sentences by classifying phonemes—fundamental units of sound in speech. The motivation for this project is rooted in accessibility: enabling individuals who are unable to verbally communicate to express themselves through thought-driven BCI systems. Using the Multi-class imagined speech classification (BCI2020) by BCI Competition Committee, this project aims to classify topographic mappings from EEG readings and enhance using a LLM for speech capabilities.

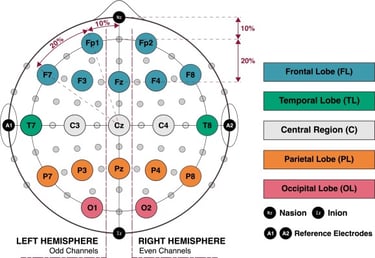
Figure 1: EEG channel positions mapped on the brain.
Methods
The project uses EEG data from BCI Competition Committee’s open-access dataset and uses their method of preprocessing data. The data consists of a 5 classes of imagined speech that map out to phrases: "Hi", "Yes", "Thank you", "Help me" and "Stop". These recorded phrases came from 15 subjects between ages 20 to 30. The EEG data has been recorded in 5 channels that target specific parts of the brain. In this project, Channel 4 will be used for subject specific channel selection.
To preprocess the data the different EEG signals are divided into overlapping windows for sequential image generation. The channels can then be mapped to construct a 2D topographic image. There are two types of topomaps experimented on: RGB and greyscale to see how well the model handles the noise.
Two deep learning architectures are developed to classify the EEG readings into the 5 classes and uses 10 fold cross validation during training.
The output is then fed into Claude Haiku 4.5, which has a custom personality configuration, to generate enriched speech - outputted by PyTTSx3.
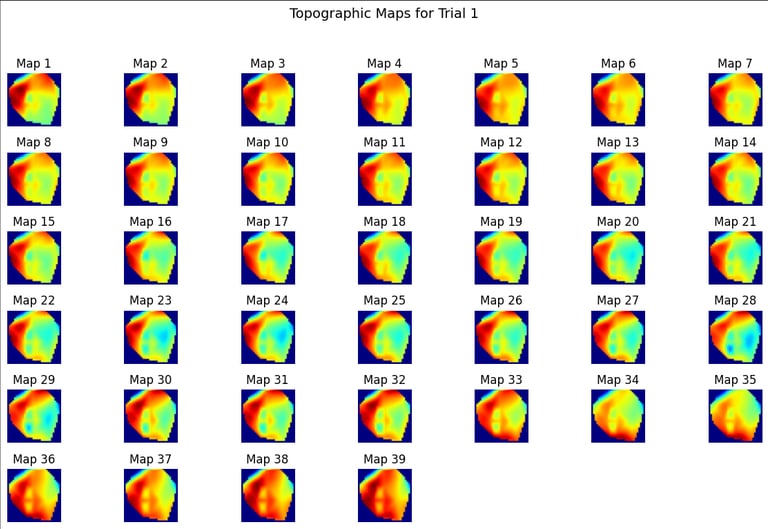
Figure 2: EEG readings transformed into topomaps.
Architecture
The dataset was split into 80%/10%/10% for training, validation and test split. Then develop two different types of deep learning architectures to train on the topomaps generated from the data - both utilizing some kind of CNN. Both models are trained with 10 fold cross validation with 150 epochs, learning rate of 0.0001, batch size of 32, and a dropout of 0.2.
Model 1: The first variation is a 3D CNN + LSTM to detect spatiotemporal EEG sequences. It uses 3 convolutional layers with max pooling with a LSTM, then dense layer and dropout regularization.
Model 2: The second variation is a 3D CNN + Transformer encoder to try and detect the same sequences. It once again uses 3 convolutional layers with max pooling, with two transformer blocks with 4 attention heads, a dense layer, and dropout.
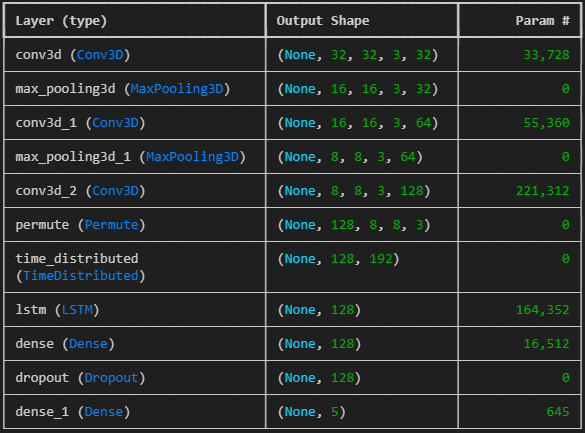
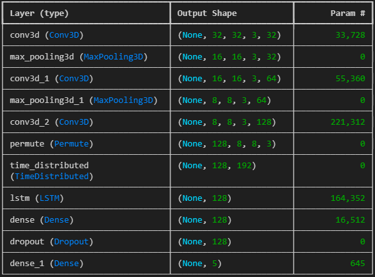
Table 1: CNN+LSTM architecture above.
Results
The CNN+LSTM performed the best achieving 83.33% overall accuracy in classification, while the CNN+Transformer model achieved an accuracy of 78.33%. The RGB topomaps have also yielded a higher accuracy in classification.
To put into more practical use cases, it can take in readings from an EEG and classify them into a phrase. The Claude Haiku model was able to provide a more flavorful output from the simple phrase enhancing: "Hi" to "Hey there! Great to meet you – I'm Edward, and I'm genuinely excited to chat with you today! What's on your mind?" and streaming it into audio in real-time.


Table 2: Metrics for CNN+LSTM model.
Table 3: Metrics for CNN+Transformer model.
Conclusion
This project demonstrates the early-stage feasibility of decoding speech from EEG data for the purpose of assistive communication. By combining EEG preprocessing, feature engineering, and deep learning through CNN architectures, it is possible to classify simple phrases with strong accuracy and enhance them into sentences. Although the system is limited by the coverage of the dataset and the absence of a real-time EEG testing environment, the results suggest that with a more comprehensive dataset and further development, this approach could form the basis of a powerful BCI communication tool for individuals with speech impairments.


Figure 3: Confusion matrix of CNN+LSTM.
References
BCI Competition Committee. (2025). Multi-class imagined speech classificatio(BCI2020) [Data set]. Kaggle. https://doi.org/10.34740/KAGGLE/DSV/11693877